قالب های فارسی وردپرس 23
این وبلاگ جهت دسترسی آسان شما عزیزان به قالب های برتر وردپرس به صورت فارسی تدوین و راه اندازی شده است.قالب های فارسی وردپرس 23
این وبلاگ جهت دسترسی آسان شما عزیزان به قالب های برتر وردپرس به صورت فارسی تدوین و راه اندازی شده است.هفت تکنولوژی نوآورانه که در سال ۲۰۱۹ بُروز آنها را شاهد خواهیم بود
در این مقاله، به اتفاقات مهم احتمالی در حوزهی فناوری نگاهی میاندازیم که درسال آیندهی میلادی شاهد آنها خواهیم بود.
۱. اخلاق در فناوری
برندهای فناوری باید رویکرد فعالانهتری در حوزهی بررسی پیامدهای اخلاقی پلتفرمها و محصولاتشان داشته باشند. در مِی۲۰۱۸ (برابر با اردیبهشت۱۳۹۷)، سازمان عفو بینالملل بیانیه تورنتورا اعلام کرد که در آن، حق استفادهی برابر و بدون هرگونه تبعیض از سیستمهای یادگیری ماشین را برای همگان محفوظ میداند. اکنون، شرکتهای مختلف متوجه این موضوع شدهاند که محصولات آنها تا چه اندازه میتواند تأثیر بهسزایی در زمینههایی از قبیل سلامت روان، افسردگی، تهدید سایبری و حتی خودکشی داشته باشد.

برنرز لی، سازندهی تارنمای جهانی یا همان اینترنت (WWW)، در گفتوگویی بیان کرده امروزه، وب به موتوری بیعدالت و تبعیض تبدیل شده است. این موتور زیر سیطرهی قدرتمندانی است که اهداف خودشان را پیش میبرند. وی معتقد است به نقطهی بیتعادلی بحرانی رسیدهایم و تغییری برای بهبود این وضعیت لازم است.
۲. فناوری در محیط شهری
شرکتهای فعال در حوزهی فناوری سعی میکنند به جزئیترین امور زندگی روزمرهی افراد توجه کنند تا راهحلی نوآورانه برای مشکلات آنها بیابند. طراحی شهری راهی برای رسیدن به آیندهای درهمتنیده با اجزای کاملا متصل به یکدیگر است.

شرکت علیبابا درحالتوسعهی لایهای مبتنی بر هوش مصنوعی است که نقش مغز شهر را ایفا خواهد کرد. این شرکت درحالآزمایش این سیستمها در یکی از شهرهای چین است. در خیابانهای شهر، هزاران دوربین بهکار گرفته میشوند تا اطلاعات لازم برای کنترل چراغهای ترافیکی و بهینهسازی جریان ترافیک و تشخیص حوادث دراختیار گرفته شود. البته این حجم از دوربینهای جمعآوری داده ممکن است خطرهایی برای حریم خصوصی افراد ایجاد کند.
۳. فناوری نزدیکونزدیکتر میشود
شرکتهای فناوری تلاش میکنند هرچه بیشتر به زندگی روزمرهی افراد نزدیک شوند تا محصولاتشان جزئی از بدن یا محیط زندگی آنان شود. این تلاشها برای ایجاد خدماتی است که به بهترین وجه با کاربر تعامل دارند. فونتهای جدید اوبر (Uber) و بلندگوهایی که صدا را بهصورت سهبعدی با محیط خانه درهم میآمیزند، همهوهمه تلاشهایی برای رسیدن به این هدف محسوب میشوند.
۴. سیستمهای بیدرنگ با قابلیت تطبیق بیولوژیکی
پیشرفتهای فناورانه موجب تولید دستگاههایی شدهاند که قابلیت تطبیق بیولوژیکی دارند. این دستگاهها در آیندهای نهچندان دور جزئی از بدن کاربر خواهند شد. تطبیق سریع این نوع افزونهها با محیط اطراف، گویای ارتقای سطح ادراک فناوری است.
شرکت پوما با همکاری مرکز طراحی دانشگاه MIT کفشی طراحی کرده که به حرکات پا و میزان خستگی فرد واکنش نشان میدهد. کفیهای این کفش با تحلیل عرق پای فرد و سایر پارامترها، اطلاعات بیولوژیکی وی را استخراج میکنند. مدارهای الکتریکی تغییرات را شناسایی می کنند و دادههایی مناسب برای جلوگیری از خستگی و بهبود عملکرد فرد ارائه می دهند.
۵. سلامتی و شبکههای اجتماعی
افزایش بیحدومرز استفاده از شبکههای اجتماعی، تأثیرات نامطلوبی بر وضعیت روحیروانی افراد گذاشته است. فشار روحی ناشی از شبکههای اجتماعی ممکن است به ناراحتی و اضطراب و افسردگی منجر شود.

تیم تحقیقاتی فیسبوک در دسامبر۲۰۱۷ (برابر با آذر۱۳۹۶) اعلام کرد وقتی افراد زمان زیادی صرف مطالعهی نوشتههای دیگران میکنند؛ ولی با آنان ارتباطی برقرار نمیکنند، احساس ناخوشایندی به آنان دست میدهد. شرکتهای تولید پلتفرمهای شبکههای اجتماعی اینچنینی درحالآگاهسازی کاربران دربارهی این شبکهها و کنترل میزان استفاده و تأثیرات آن بر افراد هستند.
۶. فرمانروایی اصوات
امروزه، گوشها به دروازههایی مهم برای غولهای فناوری تبدیل شدهاند. برای نمونه، میتوانید به میزان نفوذ شگفتانگیز ایرپادهای اپل توجه کنید. همچنین، اسپاتیفای سرویس اسپاتلایت را معرفی کرده که محتوای ویدئویی را به پادکستهای صوتی تبدیل میکند.
۷. اکوسیستمهای اوبر
در سال ۲۰۱۸، اوبر با هدف احداث اولین سیستم حملونقل هوایی درونشهری، فناوری پرواز و فرود عمودی برای ماشینهای الکتریکی (eVTOL) را معرفی کرد.

این پلتفرم درحالتلاش برای رفع تمام نیازهای کاربران است. حتی سرویس سفارش غذای این شرکت (UberEats) تا پایان سال جاری میلادی برای ۷۰درصد از شهروندان آمریکایی دردسترس خواهد بود.
پیروزی در رقابت یادگیری ماشین فقط با برتری در حوزهی داده امکانپذیر میشود
یادگیری ماشین اصطلاحی است که عموما با هوش مصنوعی نیز اشتباه گرفته میشود. این فناوری درحالتبدیل به دارایی باارزشی برای شرکتها است. بهعلاوه، شرکتهای فعال در حوزهی طراحی و بهینهسازی یادگیری ماشین، بهنوعی متوجه مشکلات اصلی آن شدهاند. آنها میدانند اجرای الگوریتمها برای هوشمندشدن در ارتباط با مرکز داده یا مسئلهای مشخص، بخش آسان کار محسوب میشود.
راهکارهای متعدد و آسان شرکتهای بزرگ برای اجرای سیستمهای یادگیری ماشین عرضه شدهاند. بهعنوان مثال، گوگل با الگوریتم متنباز تِنسورفِلو (TensorFlow) و مایکروسافت با ارائهی خدمات یادگیری ماشین در آژور (Azure) و آمازون با سرویس سِیجمِیکر (SageMaker)، قابلیتهای مذکور را به کاربران عرضه میکنند.
مقالههای مرتبط:
داده، ورودی باارزش سیستمهای یادگیری ماشین و هوش مصنوعی، تنها بخشی است که تجاری نشده است. باوجوداین، دادهها بهعنوان بازیگران مهم و تأثیرگذار در رقابت یادگیری ماشین شناخته میشوند. درواقع، پیداکردن دادهی باارزش دشواریهای زیادی دارد.
دادهی باارزش و مفید و کمیاب
شرکتها برای انجام پروژههای هوش مصنوعی و یادگیری ماشین، دادهی لازمشان را دراختیار ندارند. بههمیندلیل، داده درحالتبدیل به بازیگری تأثیرگذار در صنعت است. در دهههای گذشته، شرکتها فعالیت و موفقیت خود را برپایهی داراییهای فیزیکی و مالی، یعنی پول و اجناس تثبیت کردهاند. حتی در سال ۲۰۱۳ یک جایزهی نوبل برای طرحی در زمینهی قیمتگذاری روی داراییها درنظر گرفته شد. چنین جایزهها و رویدادهایی اولویت پرداختن به موضوعات ذکرشده را بیشازپیش کرد.

شرکتهای موفق دنیای امروز با داراییها و محصولات فیزیکی تجارت نمیکنند. بهبیاندیگر، اغلب دارایی باارزش آنها محصولاتی تحتشبکه یا نرمافزار هستند. در چهل سال گذشته، تمرکز داراییها بهطور کامل تغییر کرده است. در سال ۱۹۷۵، حدود ۸۳درصد از دارایی شرکتها اندازهگیریکردنی بود و در سال ۲۰۱۵، ۸۴درصد از داراییها اندازهگیریکردنی نبود.
اکثر شرکتهای بزرگ امروزی بهجای ساخت محصولات فیزیکی مانند ماشین لباسشویی یا قهوهساز، اپلیکیشن منتشر یا به اتصال هرچه راحتتر مردم کمک میکنند. چنین تغییراتی نوعی ناهماهنگی بین آنچه اندازهگیریکردنی است و آنچه ارزش دارد، ایجاد کرده است.
نتیجهی تغییر در ارزش واقعی شرکتها و محصولات آنها، کمبود دادهی باارزش در سطوح مشکلساز است. بهبیاندیگر، فاصلهی بین ارزشهای بازار و محاسبات مسئولان مالی دنیای کسبوکار روزبهروز بیشتر میشود. بهدلیل همین فاصلهها، شرکتها بیشتر تلاش میکنند تا از فناوری یادگیری ماشین در تصمیمهای مهمشان استفاده کنند.
برخی شرکتها حتی ارزشمندترین مشاوران خود را نیز با هدف اجرای یادگیری ماشین اخراج کردند؛ اما اکثرا به این نتیجه رسیدند که دادهی لازم آنها برای استفاده در سیستمهای هوش مصنوعی، هنوز وجود خارجی ندارد. بهعبارتدیگر، سیستمهای کنونی و فناوریها و روشهای جدید را روی همان مواداولیهی قدیمی و دادههای ضعیف پیاده میکنند.

سیستم یادگیری ماشین نیز تاحدودی مانند انسان عمل میکند؛ یعنی تا وقتی به آن آموزش ندهیم، هوشمند نخواهد شد. بهعلاوه، ماشینها برای هوشمندشدن بسیار بیشتر از انسان به داده نیاز دارند. البته، آنها قطعا این دادهها را با سرعت بسیار بیشتری درمقایسهبا انسانها میخوانند. بنابراین، با وجود رقابت شرکتها در جذب متخصصان هوش مصنوعی و اجرای برنامههای مرتبط، جنگی در پشت صحنه جریان دارد که هدف اصلی آن، دستیابی به دادههای جدید و متفاوت است.
بهعنوان مثالی از دادهی متفاوت و کاربردی در دنیای جدید، میتوان حوزهی مالی و اقتصادی را نام برد. در این حوزه، دیگر گزارشهای رسمی سازمانهای مالی خصوصی و دولتی یا آمارهای سرمایهگذاران باتجربه در تصمیمگیریهای سرمایهگذاری مفید نیستند.
دادههای جایگزین همچون حس موجود در رسانههای اجتماعی و تعداد پتنتهای ثبتشده، از دو زاویه باارزش محسوب میشوند: ۱. دادههای سنّتی روی داراییهای سنّتی متمرکز هستند که در دنیای داراییهای اندازهگیرینشدنی آنچنان ارزشمند نیستند؛ ۲. فایدهای در استفاده از یادگیری ماشین برای تحلیل دادههایی وجود ندارد که همه از آن استفاده میکنند.
بهبیانساده، جستوجو برای مزیت رقابتی در همان مواداولیهای که دیگر رقبا استفاده میکنند، سودی برای شرکتها نخواهد داشت. شرکتهای بزرگ بهجای اجرای استراتژیهای قدیمی، بهدنبال دادههای جدید و یافتن ارتباط و مزیت در آنها هستند. این سازمانها برای پیشبرد اهداف خود حتی دیتاستهای اختصاصی تولید میکنند.
به چه اطلاعاتی نیاز دارید؟
تولید داده دشوارتر از جمعآوری و هماهنگکردن و افزودن آن به مرکز داده خواهد بود. اکثر شرکتها تصور میکنند مسیر صحیح شامل جمعآوری همهی دادههای دردسترس و جستوجو و تحلیل آنها به امید یافتن راهکاری تازه است. درواقع، آنها بهدنبال نتیجه یا پیشبینی هستند که نتیجهی دلخواهشان را نشان دهد.
هوش مصنوعی و یادگیری ماشین توانایی ارائهی نتایج و تحلیلهایی دارد که شاید از عهدهی هیچ فردی برنیاید؛ اما این فناوری نمیتواند نتایج را با ثبات کامل ارائه کند. این نتیجهگیری بهمعنای شکست فناوری مذکور نیست؛ بلکه تنها باید آن را با هوشمندی بهکار گرفت. البته، اجرای آن بسیار دشوارتر از مباحث تئوری است. بهعنوان مثال، بسیاری از مدعیان ارائهی دادههای جدید و متفاوت هنوز از اندازهگیری معیارهای سنّتی برای جمعآوری داده استفاده میکنند.
قدمی که اکثر شرکتها در اجرای سیستم هوش مصنوعی و تولید داده نادیده میگیرند، تعیین اولویت است. یادگیری ماشین در اخذ بینش انسانها و توسعهی روشی سریعتر و درککردنیتر و مقیاسپذیرتر برای اجرای آن بینش مهارت دارد. انسانها نیز بینش و دیدگاه خود را با استفاده از روشهای مختلف از تخمین تجربی گرفته تا تحلیل ارتباط شرکتها بهدست میآورند.

برای بهرهبرداری از برتری یادگیری ماشین در حوزههای مذکور، نباید آن را با هر اطلاعات موجود و تقریبا مرتبطبا حوزهی فعالیت تغذیه کرد؛ بلکه دانشی منظم و ساختاریافته را به آن باید عرضه کرد. پس از ارائهی دادهی مناسب، میتوان امیدوار بود که هوش مصنوعی آن را بیاموزد و شاید مرزهایی از دانش کنونی انسان را فراتر ببرد.
بینش یادگیری ماشین با دادههای متفاوت ایجاد میشود
برای شرکتهایی که قصد دارند کاربردی تأثیرگذار از هوش مصنوعی و یادگیری ماشین را در روند کاری خود اجرا کنند، سه اصل وجود دارد.
اصل اول در اجرای سیستم یادگیری ماشین کاربردی، جمعآوری یا تولید دادهی متفاوت است. شما با کارکردن با دادههای دردسترس رقبا، به یافتهی جدیدی دست نخواهید یافت. پیش از شروع، نگاهی به داخل سازمان خود بیندازید. باید آنچه شما و اعضای گروهتان بهطور اختصاصی میدانید، بهعنوان پایههای دیتاست هوش مصنوعی استفاده شود.
اجرای یادگیری ماشین به نقاط دادهی زیادی نیاز دارد؛ اما به آن معنی نیست که مدل شما گسترهی وسیعی از اطلاعات را باید پوشش دهد. بهعبارتدیگر، پس از تغییر زمینهی مطالعهی داده، تمرکز فعالیت خود را مشخص کنید و به آن پایبند باشید.

در اصل دوم، باید ارزش دادهی معنادار درمقایسهبا دادهی جامع را درک کنید. شاید شما در روند جمعآوری داده اطلاعاتی قوی و جزئی فراهم کنید؛ اما حوزهی آن اطلاعات هیچ کاربردی برای سازمان نداشته باشد. در تعریف ساده، اگر شرکت از چنین دادههایی در فرایندهای تصمیمگیری گذشته استفاده نکرده، آنها فایدهای برای سیستم یادگیری ماشین هم نخواهند داشت.
متخصص حرفهای حوزهی یادگیری ماشین پیش از معماری سیستم، از مدیران شرکت سؤالهایی دشوار دربارهی زمینههای مهم میکند. بهعلاوه، او باید بداند زمینههای مهم چگونه در بهکارگیری نتایج استخراجشده از هوش مصنوعی استفاده میشوند. اگر پاسخ به سؤالهای متخصص برای شرکتتان دشوار باشد، درنتیجه هنوز تفکر لازم دربارهی ایجاد ارزش کاربردی از این حوزه را بهکار نگرفتهاید.
اصل سوم بهکارگیری یادگیری ماشین به این نکته تأکید میکند که از دانش خود برای شروع کار استفاده کنید. شرکتهای موفق در اجرای سیستمهای یادگیری ماشین فرایند را با بینش اختصاصی خود دربارهی اولویت اصلی کاری در تصمیمگیریها شروع میکنند. شروع از این مرحله به آنها در انتخاب دادهها برای جمعآوری و فناوریهای لازم کمک میکند.
نقطهی مناسب برای شروع فرایند یادگیری ماشین، مقیاسدهی و رشد دانشی است که درحالحاضر، در تیم وجود دارد. رشد آن دانش در مسیر تولید ارزش برای شرکت مفید خواهد بود.
نکتهی کاملا واضح آن است که نرمافزار جهان را خورده است. این اصطلاح را مارک اندرسن، کارآفرینحوزهی نرمافزار، بیان کرده است. البته، پدیدهی جوان دنیای فناوری هنوز سیر نیست و به رژیمی بهتر متشکل از دادههای جدید و فناوریهای نوین نیاز دارد. با چنین رژیم جدیدی میتوان هنوز با نرمافزار ارزش خلق کرد.
شمارش تعداد پنلهای خورشیدی به کمک هوش مصنوعی
شمارش کل پنلهای خورشیدی موجود در ایالات متحده بهصورت دستی، تقریبا کار غیرممکنی است؛ اما خوشبختانه، تکنولوژی بهاندازهی کافی پیشرفت کرده که در این زمینه، ما را یاری کند! پژوهشگران دانشگاه استنفورد برای شمارش تعداد پنلها، هوش مصنوعی را پیشنهاد میکنند. آنها الگوریتمی مبتنی بر هوش مصنوعی به نام DeepSolar طراحی کردهاند که تمام ۱.۴۷ میلیون پنل خورشیدی در آمریکا را شناسایی و شمارش میکند.
بهموجب راهکار پژوهشگران استنفورد، شبکهی عصبی دیجیتالی تصاویر تهیهشده توسط ماهوارهها به کاشیهای کوچکتری تبدیل شده و پیکسلهای موجود در هر یک از این کاشیها دستهبندی میشوند. سپس با تحلیل پیکسلهای قرارگرفته درکنار هم متوجه میشود که آیا سطح مدنظر از پنل خورشیدی تشکیل شده است یا نه؛ خواه با مزرعهای از پنلهای خورشیدی مواجه باشیم یا با یک پنل خورشیدی تنها در سقف یک مجتمع مسکونی.

در روش مبتنی بر هوش مصنوعی، از خطاهای انسانی جلوگیری میشود، دقت کار بالا میرود و مهمتر از همه، کار شمارش با حداکثر سرعت و کارایی انجام میشود. شمارش پنلهای خورشیدی با این روش تنها چند هفته طول میکشد؛ اما در روشهای عادی ممکن است ماهها و حتی سالها به طول بیانجامد، بدین ترتیب ممکن است اطلاعات نادرستی به دست آوریم؛ زیرا در این حین احتمالا پنلهای جدیدی نصب شدهاند که فرایند شمارش را طی نکردهاند.
شمارش سریع پنلهای خورشیدی به دولت در زمینههای مختلفی کمک میکند؛ بهعنوان مثال با استفاده از دادههای این شمارش، دولت دربارهی استراتژیهای خود در زمینهی انرژیهای تجدیدپذیر تصمیمگیری میکند، ضریب نفوذ پنلهای خورشیدی در بین مردم را اندازهگیری میکند و حتی با استفاده از تحلیل تعداد پنلهای هر منطقه، وضعیت اقتصادی مردم آن منطقه را بررسی میکند.
البته پیش از انجام شمارش، احتمالا پیشبینیهایی وجود دارد. مثلا میتوان گفت که تعداد پنلها در کالیفرنیا و قسمتهای جنوب غربی از سایر مناطق بیشتر است؛ زیرا این محدوده، منطقهای آفتابی است. پژوهشگران به نتایج دیگری نیز دست یافتند. مثلا متوجه شدند که در مناطقی که شدت تابش آفتاب از حد خاصی بالاتر است، به احتمال بسیار زیاد پنل خورشیدی وجود دارد. در این مناطق، شرکتها احتمالا هزینههای نصب پنل خورشیدی را کاهش میدهند تا تعداد نصبها به میزان قابلتوجهی افزایش یابد.
البته موانعی هم بر سر راه تکنولوژی DeepSolar وجود دارد؛ مثلا شمارش پنلها با استفاده از تصاویر تهیهشده توسط ماهوارهها، اطللاعات مفیدی دربارهی ویژگیهای پنلها در اختیار ما قرار نمیدهد یا مشخص نمیکند که پنلها قدیمی هستند یا جدید. احتمالا در آیندهای نزدیک شاهد سیستمهای مبتنی بر هوش مصنوعی خواهیم بود که این مشکلات را نیز حل خواهند کرد.
پیوند کلان داده با هوش مصنوعی، کلید موفقیت کسب و کارها در دنیای امروز
سیستمهای نرمافزاری تجاری همچون سرویسهای ERP و CRM به نقطهای رسیدهاند که سوددهی آنها بهمرور درحال کاهش است. بهبیان دیگر، ورودی این سیستمها همچون ورودیهای انسانی یا دادههای استخراجشده براساس رخدادهای مشخص، به حداکثر رشد خود رسیدهاند.
استفاده از سرویسهای نرمافزاری مدیریت و اتوماسیون کسبوکارها، به نقطهای از کارایی رسیده است که ارزش افزودهی آن، وابسته به فرایندهای داخلی شرکتها همچون تعامل گروههای کاری میشود. چنین روش کاری، درنهایت منجر به استفاده از نرمافزارها در دادههای فوقحساس یا تأثیرگذار روی روندهای مالی و ارائهی ارزش بیشتر به مشتریها، نخواهد شد.
اکنون زمان آن رسیده است که داده را هرچه بیشتر به درآمدزایی مرتبط و متصل کنیم. مدلهای کسبوکاری مدرن، پیرامون پلتفرمهای هوشمندی شکل میگیرند که با استفاده از هوش مصنوعی، موانع مختلف را از سر راه بر میدارند، سیستمهای متفاوت را به هم وصل کرده و ناممکنهای پیشین یا دادههای دشوار و پیچیده را رمزگشایی میکنند. چنین مدلی، منبعی صحیح برای کسب نتایج مالی و درآمدی محسوب میشود.
مقالههای مرتبط:
صنایع سنگین و سنتی درحال تغییر هستند. شرکتهای موفق قدیمی همچون کاترپیلارو برکشایر هاتاوی، چرخهی وابستگی به فناوریهای اولیه را شکستهاند. درعوض، آنها منابع دادهی اختصاصی خود را تولید میکنند. چنین رویکردی، پیش از این در میان کسبوکارها بهندرت دیده شده است.
بهخاطر منافع کشف شده از بهکارگیری بهینهی فناوری، مدیران کسبوکارهای صنعتی بهسرعت درحال تغییر تمرکز به انقلاب دیجیتال هستند. آنها، فرصتهای قابلتوجه در بازار جدید را کشف کرده و با استفاده از آنها، در زمان و هزینههای خود صرفهجویی میکنند. چنین صرفهجویی، با افزایش کارایی و بازدهی عملیاتی بهدست میآید.

اتصال داده به درآمد
مثالهای متعددی در دنیای کسبوکار امروزی، در ارتباط با پیادهسازی فناوری در صنایع سنتی دیده میشود. نقطهی مشترک، عدم توانایی اکثر فناوریها در کمک به بهبود عملیات حیاتی همچون تعمیر و نگهداری، مهندسی، مالی و خدمات مشتری است. چنین کاربردهای ناموفقی در فناوری، موجب از بین رفتن تلاشهای مدیران بخش اطلاعات شرکتها و هزینههای صرفشده برای هماهنگی سیستمها نیز میشود.
رهبران کسبوکارها، در بهکارگیری فناوریهای جدید اغلب در دام عدم تفکر کافی میافتند. آنها بدون اینکه بدانند چه دادهای برای راهاندازی کسبوکار مناسب است، آن را به سیستمهای فناوری اطلاعات متصل میکنند. در بهترین حالت، چنین رویکردی نتایج زیادی نخواهد داشت. در بدترین حالت نیز، بدون کسب هیچ نتیجهای، تنها سرمایه و زمان شرکت از بین رفته است.
تیمهای عملیاتی در کسبوکارهای مختلف، به تکههای متفاوتی از فناوری تکیه دارند که بهندرت با هم ارتباط برقرار میکنند. درواقع، اعضای گروهها نمیتوانند با یادگیری بیشتر اطلاعات یک حوزه، هیچ کمکی به پیشرفت حوزههای نزدیک یا مجاور آن، بکنند. چنین پیشرفت و کمکی، نیاز به دادههای ماشینی با ارزش دارد که حقایق مالی و مزیتهای داراییها و تجهیزات شرکت را روشن کنند.
بههرحال، روشهای قدیمی در استفاده از فناوریها، نمیتوانند اهداف سازمانی کنونی را برآورده کنند و نتایج مالی قابلتوجهی نیز ندارند. بهعلاوه، آنها توانایی ایجاد انعطاف یا چابکی مورد نیاز برای پیروزی در بازارهای کنونی را نیز ندارند. درنهایت، کسبوکارها بهوسیلهی خودشان محدود میشوند. محدودیت، بهخاطر سرعت پایین نوآوری و کنجکاوی مفید ایجاد میشود و از همه مهمتر، یک مانع بر سر راه موفقیت است.
خبر خوب آنکه روندهای سنتی را میتوان با راهکارهایی خاص بهبود داد. البته، کسبوکارهای امروزی، دادههای ارزشمندی که سیستمهای سنتیشان قادر به جمعآوری یا استفاده نیستند، نادیده میگیرند. درواقع برای بهبود روند کنونی، در قدم اول نیاز به شناسایی دادههای کاربردی داریم.
تفاوت دادهی کاربردی و غیرکاربردی
کلانداده در حالت اولیه و خام خود، قابلیت استفاده برای اهداف کاربردی را ندارد. درواقع، برای بهکارگیری داده باید یک نکتهی مهم را در مرحلهی جمعآوری در نظر داشته باشیم. هر دادهای که قابل شمارش و جمعآوری باشد، لزوما با ارزش نبوده و هر دادهی باارزش نیز، لزوما قابل اندازهگیری و شمارش نیست. بهخاطر همین اصلی اولیه، انسانها همیشه در سیستمهای هوش مصنوعی نیز بازیگرانی حیاتی محسوب میشوند.
در دهههای گذشته، دادههای کسبوکارها که هیچ استفادهای از آن نمیشد، بحث اصلی دنیای داده بود. بههرحال این موارد موجب پیشرفت شرکتهای عرضهکنندهی سرور، خدمات ابری و محصولات ذخیرهسازی شد. البته، امروز میدانیم که برای بهرهبرداری هرچه بیشتر از آن منابع، باید دادههای صحیح را در زمان صحیح و برای اهداف صحیح بهکار بگیریم.
یک پلتفرم هوشمند، کارهای تکراری و وقتگیر را انجام میدهد. با استفاده از هوش مصنوعی ویادگیری ماشین که با هدف مخصوص به هر کسبوکار طرحی میشود، وظایف پیچیدهی آمادهسازی، پاکسازی و استخراج دادهی مفیدتر انجام میشود. درواقع، هوش مصنوعی دادهی کاربردی را از دادهی غیرکاربردی جدا میکند. روندی که شبیه به تشخیص سیگنال مفید از نویز است. با جداسازی دادهی کاربردی، فاکتورهای مهم برای شرکت (KPI)، به دادههای متصل میشوند و اقتصاد شرکت، بهبود مییابد.
هوش مصنوعی توانایی پیشبینی مناطق اعیاننشین در شهرها را دارد
در یک دههی گذشته، نگرانی از اعیانیشدن (Gentrification) مناطق شهری در کشورهای گوناگون افزایش یافته است. یکی از دلایل اصلی این افزایش نگرانی، بازگشت بیشازپیش افراد تحصیلکرده و متمول به شهرها محسوب میشود.
سوالی که نقطهی تلاقی تصمیمگیران سیاستهای شهری و دنیای فناوری میشود آن است که آیا هوش مصنوعی، میتواند سرعت و الگوی اعیاننشین شدن را در شهرها پیشبینی کند؟ تحقیقی جدید با همکاری دانشمندان علوم داده و جغرافیدانها، چنین قابلیتی را برای هوش مصنوعی متصور میشود.
جاناتان ریدز، جوردن دِسوزا و فیل هابارد از کالج سلطنتی لندن در تحقیقی، توانایی هوش مصنوعی را در موضوعات شهری بررسی کرده و نتایج را در ژورنال Urban Studies منتشر کردهاند. در این تحقیقات، از یادگیری ماشین و روند معمول آن استفاده شد. روند معمول یادگیری ماشین، مطالعهی رخدادهای گذشته و پیشبینی چگونگی رویدادهای مشابه در آینده است. در تجربهی مذکور، محققان اطلاعات اعیانیشدن مناطق در لندن را بررسی کردند تا الگوی آن را برای آینده، پیشبینی کنند.
برای بررسی دقت هوش مصنوعی، تیم تحقیقاتی ابتدا صحت پیشبینیهای آن را برای سال ۲۰۱۱ بررسی کردند. روند کار به این صورت بود که اطلاعات سال ۲۰۰۱ شهر لندن، برای پیشبینی صحیح رخدادهای سال ۲۰۱۱ تحلیل و بررسی شد. سپس، از این مدل برای پیشبینی الگوی مناطق در سال ۲۰۲۱ استفاده شد.

در ابتدای تحقیقات، معیارهای کنونی اجتماعی و اقتصادی براساس چهار عامل اصلی اندازهگیری شدند: درآمد خانواده، ارزش املاک و مستغلات، سهم فرد و خانواده از مشاغل با سطح کلاس بالا و کسب اعتبار برای مشاغل. کسب اعتبار برای مشاغل بهمعنای سهم شهروندان از رسیدن به سطحی از مهارتهای شغلی است.
محققان پس از بررسی وضعیتهای اقتصادی و اجتماعی برای هر منطقه، تأثیر عوامل دموگرافیک دیگر همچون سن و قومیت را نیز بر اعیاننشینی مطالعه کردند.
هوش مصنوعی پس از مطالعه و بررسی دادههای سال ۲۰۰۱، با نتایجی بسیار نزدیک به رخدادهای واقعی برای سال ۲۰۱۱، کار خود را به پایان رساند. یک نتیجهی آماری بسیار نزدیک به واقعیت، حاصل استفاده از هوش مصنوعی شد. درواقع استفاده از هوش مصنوعی و یادگیری ماشین، از تمامی روشهای آماری سنتی همچون تحلیل رگرسیون استاندارد، دقیقتر بود.

نتایج تحقیقات نشان داد که عوامل دموگرافیک اصلی مانند درآمد زوجین بدون داشتن فرزند، مالکیت خودرو یا حتی قومیت، در فهرست برترین عوامل مؤثر بر اعیاننشینی قرار نداشتند. در فهرست فاکتورهای مؤثر، مهاجرت جای داشت که البته آن هم تنها برای مهاجران از مبدأ دیگر کشورها در اتحادیهی اروپا، آمریکا، استرالیا و نیوزیلند صحیح بود.
نوع ساختمانها، خصوص انواع قدیمی یا با معماری مشهور به Terraced، بر پیشبینیها تأثیر داشت. درنهایت، محققان به این نتیجه رسیدند که اکثر عوامل مهم و تأثیرگذار بر پیشبینیها، به اشتغال مرتبط بودند. مواردی همچون ساعتهای کاری زیاد، مهارت و مدرک کاری، تنوع شغلی مانند کار کردن در خانه یا خوداشتغالی، موارد مهم تأثیرگذار بر عوامل پیشبینی بودند.
تصویر زیر، نشاندهندهی اعیاننشین شدن مناطق در سال ۲۰۱۱ است. نتیجهگیری نمودار زیر، با بررسی تغییر در ثابتهای اقتصادی و اجتماعی در سطح منطقهای انجام شد. باتوجهبه تصویر، دو خط اعیاننشینی را میتوان از مرکز لندن تشخیص داد. یکی از آنها بهسمت جنوب غربی و دیگری بهسمت شمالشرقی رفته است. خطوط ایجادشده، بهنام خط میلیاردرها (Billionaire's Row) شناخته میشوند.
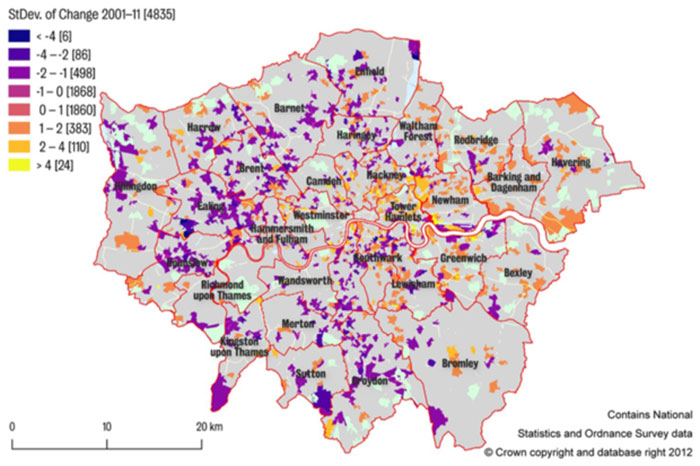
منطقهی مشخصشده با رنگ صورتی تیره، شاهد کاهش ثابتهای اجتماعی-اقتصادی بود؛ درحالیکه در مناطق زردرنگ، افزایش شاخصها اتفاق افتاد. مناطق سبز کمرنگ، مکانهایی هستند که تغییرات بسیار کوچکی در ثابتهای اجتماعی-اقتصادی آنها رخ داده است. نکتهی قابلتوجه آن است که حتی مناطق ثروتمندنشین هم تغییر و اعیاننشینی را در این مدت تجربه کردهاند.
تصویر بعدی، پیشبینی اعیاننشینشدن در سال ۲۰۲۱ را ارائه میکند. در این نقشه نیز، اعیاننشینی با تغییر در ثابتهای اجتماعی و اقتصادی پیشبینی شده است. در تصویر زیر، اعیاننشین شدن نهتنها در مناطق وستمینستر، کنزینگتون و چلسی پیشبینی میشود، بلکه مناطق با سطح زندگی کارگری نیز هدف بعدی آن خواهند بود.
نکتهی مهم دیگر در پیشبینی سال ۲۰۲۱ لندن، توسعهی اعیاننشینی به مناطق و شهرهای حومه است. طبق پیشبینی انجامشده، بالاتر رفتن سطح زندگی در یک منطقه، احتمالا موجب جابهجایی ساکنان از مناطق دیگر و کاهش معیارها در آن بشود. در این تصویر هم مناطق صورتی پررنگ، نشاندهندهی کاهش و مناطق زرد، نشاندهندهی افزایش شاخصهای اقتصادی و اجتماعی است.
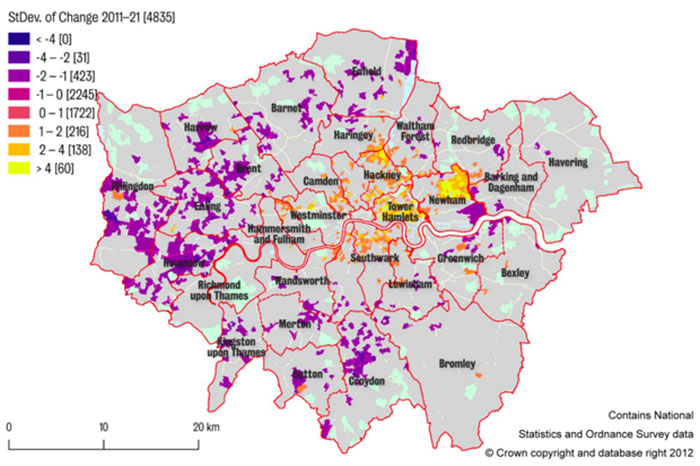
مدل پیشبینی سال ۲۰۲۱، نشان میدهد که سرعت اعیاننشین شدن مناطق تا آن سال، بهمرور آهسته میشود. شایان ذکر است مناطقی که از سال ۲۰۰۱ تا ۲۰۱۱ بیشترین تغییرات را شاهد بودند، تا سال ۲۰۲۱، تغییرات کمتری خواهند داشت. درواقع اگرچه شاخصهای این مناطق تا سال ۲۰۲۱ رشد میکند، اما سرعت آن افزایش نخواهد یافت.
تیم تحقیقاتی امید دارد که نتایج خود را در آینده با بررسی اطلاعات زندهی بیشتر، دقیقتر کند. آنها از دادههایی همچون قیمت لحظهای املاک در وبسایتهای متعدد تا نمادهای فرهنگی مصرفگرایی در توییتر، برای پیشبینی دقیقتر مناطق با ظرفیت اعیاننشین شدن، استفاده خواهند کرد.